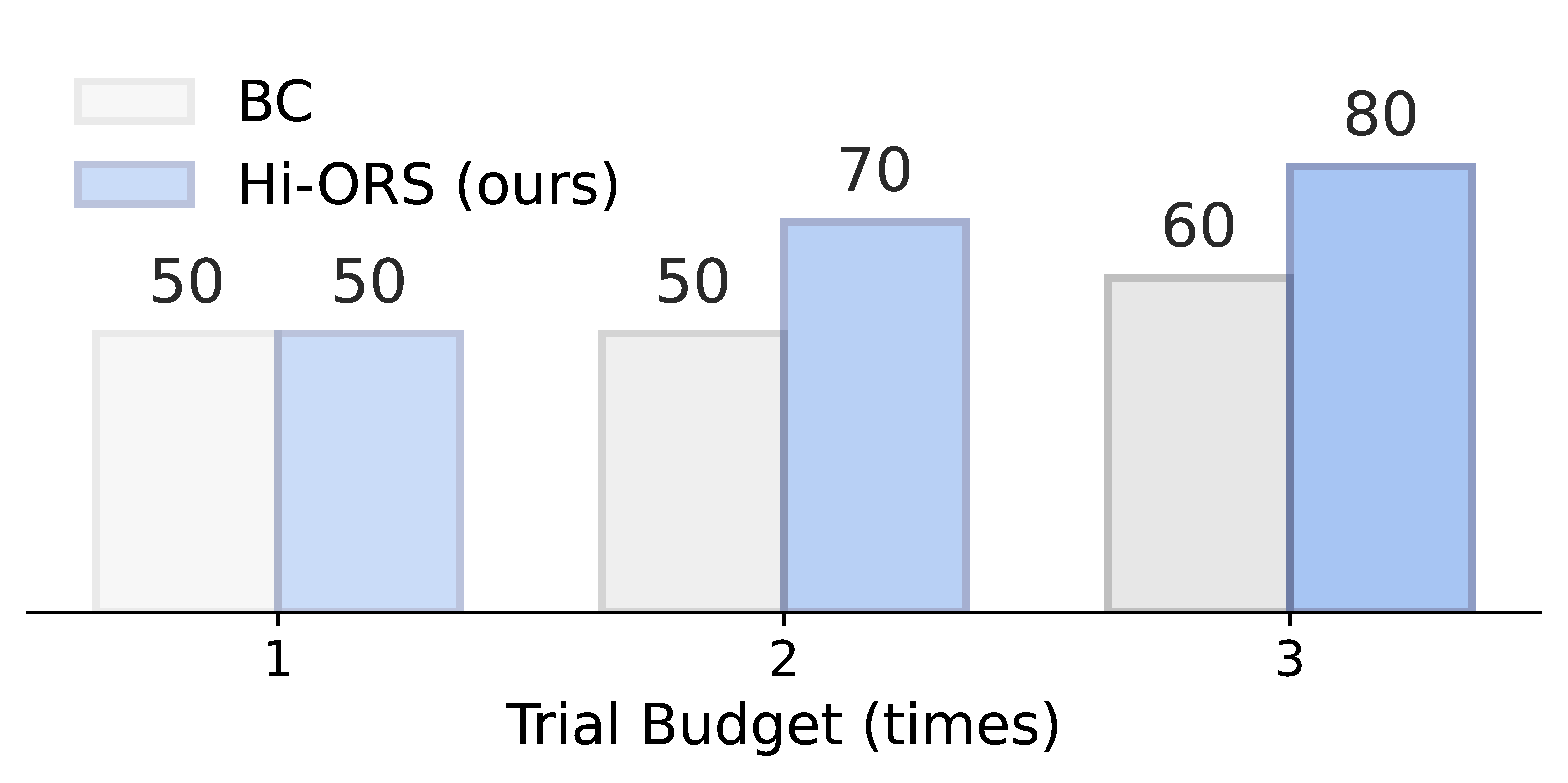
Reinforcement learning (RL) is widely used to produce robust robotic manipulation policies, but fine-tuning vision-language-action (VLA) models with RL can be unstable due to inaccurate value estimates and sparse supervision at intermediate steps. In contrast, imitation learning (IL) is easy to train but often underperforms due to its offline nature. In this paper, we propose Human-in-the-loop Online Rejection Sampling (Hi-ORS), a simple yet effective post-training method that utilizes rejection sampling to achieve both training stability and high robustness. Hi-ORS stabilizes value estimation by filtering out negatively rewarded samples during online fine-tuning, and adopts a reward-weighted supervised training objective to provide dense intermediate-step supervision. For systematic study, we develop an asynchronous inference-training framework that supports flexible online human-in-the-loop corrections, which serve as explicit guidance for learning error-recovery behaviors. Across three real-world tasks and two embodiments, Hi-ORS fine-tunes a pi-zero base policy to master contact-rich manipulation in just 1.5 hours of real-world training, outperforming RL and IL baselines by a substantial margin in both effectiveness and efficiency. Notably, the fine-tuned policy exhibits strong test-time scalability by reliably executing complex error-recovery behaviors to achieve better performance.